# -*- coding: utf-8 -*-
#pip install selenium
#pip install beautufulsoup4
from bs4 import BeautifulSoup
from selenium import webdriver
import requests
import time
import pandas as pd통찰력
1. 페이지 이동 시 URL 패턴 이해
2. 커버 루프
3. 모듈화
'추천 관련글,
1-1 기본 URL
1-2 버튼 클릭 시 URL
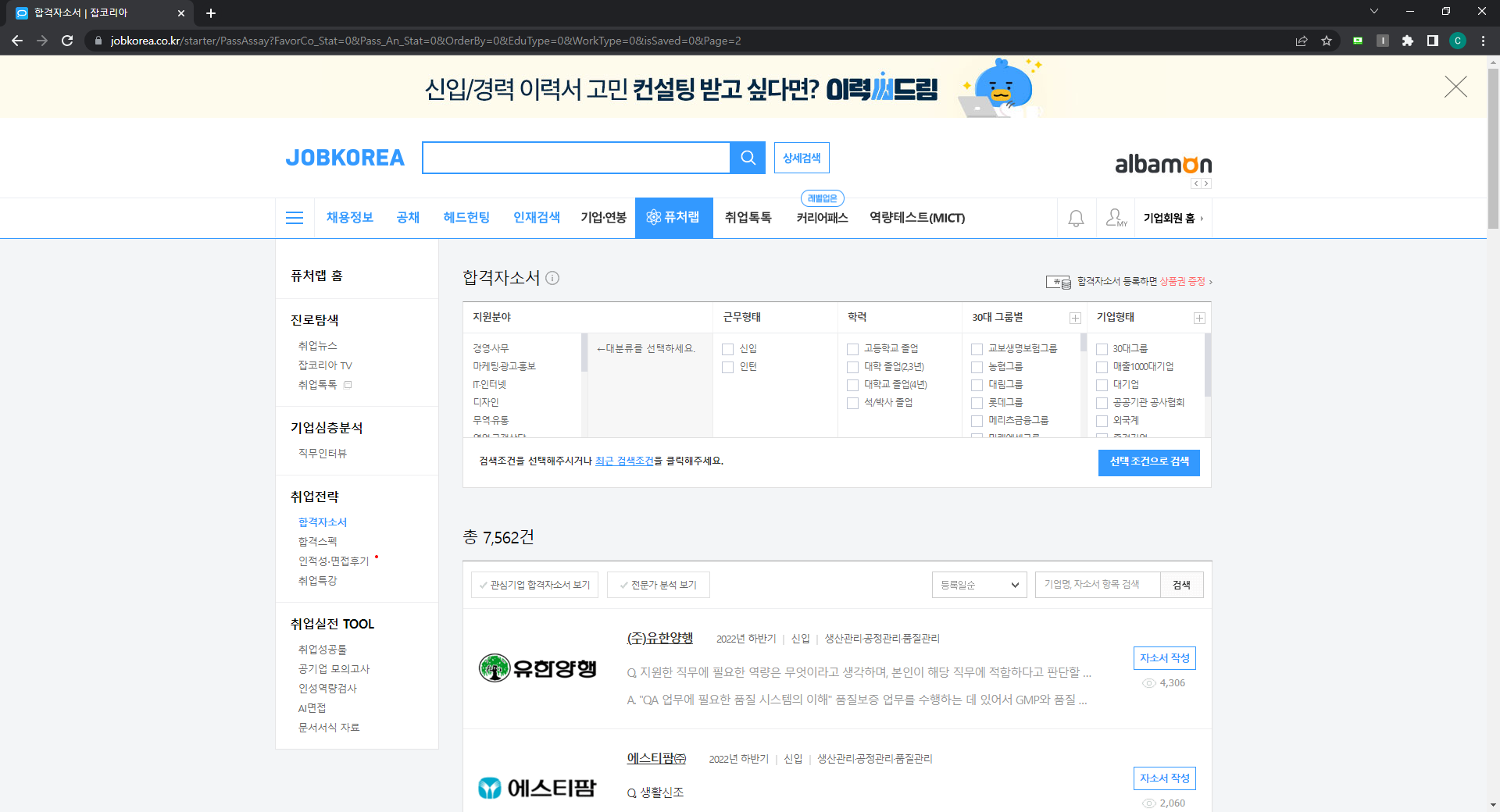
1-3 한 페이지만 요청한 경우

1-4 불필요한 코드 제거
search_url="https://www.jobkorea.co.kr/starter/PassAssay?FavorCo_Stat=0&Pass_An_Stat=0&OrderBy=0&EduType=0&WorkType=0&isSaved=0&Page=1"
search_url = f'https://www.jobkorea.co.kr/starter/PassAssay?Page={pagenum}'뒤에 있는 for 루프의 페이지 번호로 이동
2. 원본 코드
더보기
#서칭된 url이 상대경로 이기때문에 앞부분 url을 따로 저장
pre_url="https://www.jobkorea.co.kr/"
#드라이버 실행
driver = webdriver.Chrome('/chromedriver/chromedriver.exe')
#url 접근
search_url="https://www.jobkorea.co.kr/starter/PassAssay?Page=1"
driver.get(search_url)
#드라이버 현재 URL 로드 해서 response 객체에 저장
response = requests.get(driver.current_url)
# 뷰티풀소프를 이용해서 html 파싱
soup = BeautifulSoup(response.text, 'html.parser')
#url 리스트 객체 생성
names = ()
fields = ()
urls = ()
# 웹 스크래핑한 결과에서 필요한 정보를 추출하여 각 리스트에 저장
for name in soup.select('.titTx'):
names.append(name.text.strip())
for field in soup.select('.field'):
if field.text.strip() not in ('인턴', '신입'):
fields.append(field.text.strip())
for url in soup.find_all('p', {'class': 'tit'}):
urls.append(pre_url + url.find('a')('href'))
# 판다스 데이터프레임으로 저장
data = {'name': names, 'field': fields, 'url': urls}
df = pd.DataFrame(data)
df.head()
driver.quit()2-1 이동 후 변수 추가
#서칭된 url이 상대경로 이기때문에 앞부분 url을 따로 저장
pre_url="https://www.jobkorea.co.kr/"
#드라이버 실행
driver = webdriver.Chrome('/chromedriver/chromedriver.exe')
#url 리스트 객체 초기화
names = ()
fields = ()
urls = ()
for i in range(1,5):
pagenum = i
print(i)
#url 접근
search_url = f'https://www.jobkorea.co.kr/starter/PassAssay?Page={pagenum}'
driver.get(search_url)
# web loading 대기
time.sleep(1)
# 드라이버 현재 URL 로드 해서 response 객체에 저장
response = requests.get(driver.current_url)
# 뷰티풀소프를 이용해서 html 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 웹 스크래핑한 결과에서 필요한 정보를 추출하여 각 리스트에 append
for name in soup.select('.titTx'):
names.append(name.text.strip())
for field in soup.select('.field'):
if field.text.strip() not in ('인턴', '신입'):
fields.append(field.text.strip())
for url in soup.find_all('p', {'class': 'tit'}):
urls.append(pre_url + url.find('a')('href'))
# 판다스 데이터프레임으로 저장
data = {'name': names, 'field': fields, 'url': urls}
df = pd.DataFrame(data)– 결과 확인
– URL을 저장하는 중에 오류가 발생했습니다.
pre_url /제거
3. 모듈화
def in_data_url(start_page, end_page):
#서칭된 url이 상대경로 이기때문에 앞부분 url을 따로 저장
pre_url="https://www.jobkorea.co.kr"
#드라이버 실행
driver = webdriver.Chrome('/chromedriver/chromedriver.exe')
#url 리스트 객체 초기화
names = ()
fields = ()
urls = ()
for i in range(start_page,end_page+1):
pagenum = i
print(i)
#url 접근
search_url = f'https://www.jobkorea.co.kr/starter/PassAssay?Page={pagenum}'
driver.get(search_url)
# web loading 대기
time.sleep(1)
# 드라이버 현재 URL 로드 해서 response 객체에 저장
response = requests.get(driver.current_url)
# 뷰티풀소프를 이용해서 html 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 웹 스크래핑한 결과에서 필요한 정보를 추출하여 각 리스트에 append
for name in soup.select('.titTx'):
names.append(name.text.strip())
for field in soup.select('.field'):
if field.text.strip() not in ('인턴', '신입'):
fields.append(field.text.strip())
for url in soup.find_all('p', {'class': 'tit'}):
urls.append(pre_url + url.find('a')('href'))
# 판다스 데이터프레임으로 저장
data = {'name': names, 'field': fields, 'url': urls}
df = pd.DataFrame(data)
driver.quit()
return df
df_url = in_data_url(5,10)
df_url.info()
df_url.tail()시험
확인